🟢 Architektur
Die Architektur von dataCycle folgt einem klaren Grundgedanken:
Daten werden einmal zentral strukturiert – und anschließend von beliebigen Systemen genutzt.
Um dieses Ziel zu erreichen, trennt dataCycle konsequent:
- Datenquellen von Datenhaltung
- Datenstruktur von Darstellung
- Datenpflege von Datennutzung
Diese Trennung ist die Grundlage dafür, dass Daten langfristig konsistent, flexibel und wiederverwendbar bleiben.
Die folgende Grafik zeigt diesen Aufbau schematisch.
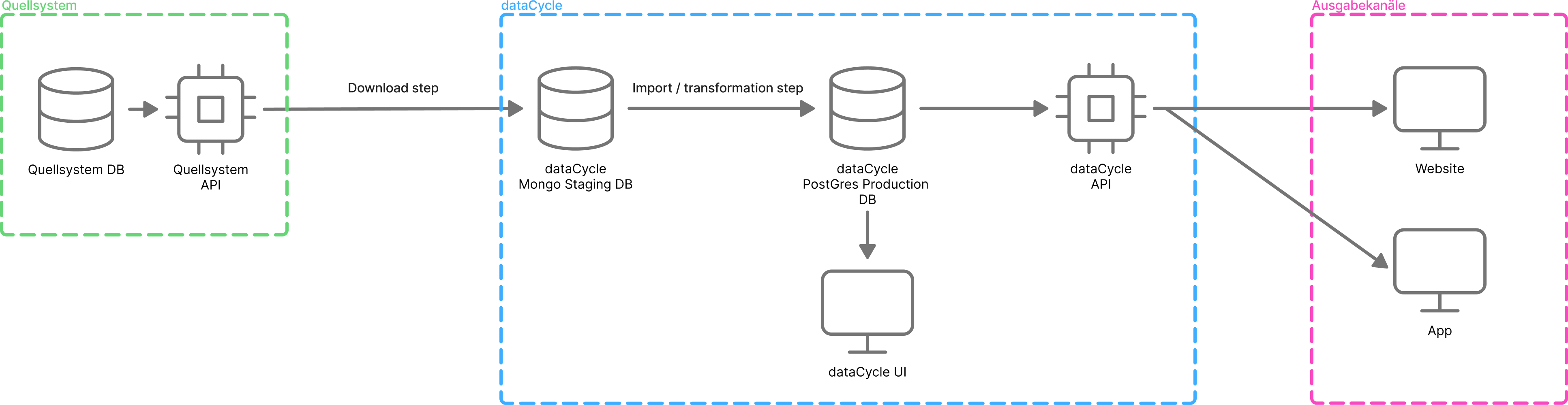
Abbildung: dataCycle als zentrale Plattform zwischen Quellsystemen und Ausgabekanälen
Quellsysteme – Ursprung der Daten
Section titled “Quellsysteme – Ursprung der Daten”Auf der linken Seite der Architektur befinden sich die Quellsysteme. Das sind externe Systeme, in denen Daten entstehen oder bereits gepflegt werden, z. B.:
- Fach- und Redaktionssysteme (z. B. touristische Informationssysteme oder CMS)
- Plattform- und Drittsysteme (z. B. Buchungs-, Event- oder Tourenplattformen)
- Medien- und Asset-Systeme (z. B. Bild- oder Mediendatenbanken)
- CRM-, GIS- oder Infrastruktursysteme
Diese Systeme liefern die Rohdaten, die über spezialisierte dataCycle Connectoren in dataCycle übernommen werden.
dataCycle kann solche Systeme ergänzen oder – je nach Projekt – auch teilweise ersetzen.
In der Praxis werden Quellsysteme jedoch häufig beibehalten, da sie oft eigene Benutzeroberflächen oder spezifische Funktionen mitbringen.
👉 dataCycle integriert sich in diese bestehende Systemlandschaft und sorgt für eine zentrale, strukturierte Datenbasis.
Import, Standardisierung & Transformation
Section titled “Import, Standardisierung & Transformation”Die Übernahme der Daten aus den Quellsystemen erfolgt über den sogenannten Download Step.
Nach der technischen Übernahme durchlaufen die Daten einen mehrstufigen Import- und Transformationsprozess.
Dabei werden die Daten:
- in ein einheitliches, schema.org-konformes Datenmodell überführt
- strukturiert und normalisiert
- validiert und qualitätsgesichert
- mit Metadaten, Klassifizierungen und Relationen angereichert
- bestehende Duplikate zusammengeführt (sofern konfiguriert)
Dieser Schritt ist zentral für dataCycle:
Unterschiedliche Datenformate und Strukturen werden auf einen gemeinsamen Standard gebracht.
So entsteht eine stabile, konsistente Datenbasis, auf die sich alle nachgelagerten Prozesse und Ausgabekanäle verlassen können.
dataCycle Kernplattform – Zentrale Datenarbeit
Section titled “dataCycle Kernplattform – Zentrale Datenarbeit”Sobald Daten in dataCycle verfügbar sind – sei es über Importprozesse oder durch manuelle Erstellung – beginnt die eigentliche fachliche, organisatorische und redaktionelle Arbeit.
Hier wird Datenmanagement von einer rein technischen Aufgabe zu einer dauerhaften organisatorischen Disziplin.
Die dataCycle Kernplattform bildet das Zentrum für:
-
Erfassung und redaktionelle Pflege von Daten (inkl. manueller Erstellung, Ergänzung und Korrektur)
-
Validierung und Qualitätssicherung durch Regeln, Reports, Workflows und Qualitätskennzahlen
-
Anreicherung und Strukturierung von Daten z. B. durch Klassifizierungen, Relationen, Overlays, Aggregate sowie Rollen- und Rechtekonzepte
-
Zusammenstellung und Bereitstellung von Datensammlungen für APIs, Widgets, Anwendungen und weitere Ausgabekanäle
-
Lifecycle-Management von Daten inkl. Versionierung, Historie, Archivierung und Ablöse
In dieser Phase wird deutlich:
Nachhaltiges Datenmanagement hängt nicht nur von Tools ab, sondern von klaren Strukturen, Verantwortlichkeiten und Prozessen.
Diese Perspektive wird im Konzept der dataJourney weiter vertieft.
Ausgabekanäle – Nutzung der Daten
Section titled “Ausgabekanäle – Nutzung der Daten”Auf der rechten Seite der Architektur befinden sich die Ausgabekanäle.
Aus dataCycle heraus können Daten konsistent bereitgestellt werden, z. B. für:
- Websites
- Apps
- APIs
- Widgets
- Kartenanwendungen
- weitere angebundene Systeme
Alle Ausgabekanäle greifen dabei auf dieselbe zentrale Datenbasis zu.
Sie müssen sich nicht mehr mit:
- unterschiedlichen Datenformaten
- variierenden Strukturen
- projektspezifischen Sonderlösungen
auseinandersetzen, sondern können sich vollständig auf Darstellung und User Experience konzentrieren.
👉 Für technische Details zur Anbindung siehe API Übersicht.
Zusammengefasst
Section titled “Zusammengefasst”Die Architektur von dataCycle sorgt dafür, dass:
- Daten nicht mehrfach modelliert oder gepflegt werden müssen
- neue Kanäle ohne strukturelle Anpassungen angebunden werden können
- Daten über Jahre hinweg konsistent nutzbar bleiben
dataCycle bildet damit das stabile Rückgrat für datengetriebene Anwendungen, Plattformen und digitale Produkte.
👉 Weiterführend:
- Produktüberblick – Module & Connectoren
- Use Cases – konkrete Anwendungsszenarien
- API – technische Integration